


인공지능 시대에 더욱 빛을 보게 되는
우리의 문화유산
한 겨울을 지나고 봄이 다가오면서 가슴까지도 따뜻해지는 자연의 변화를 느끼고 있다. 하지만 한겨울에도, 지금 이 순간에도 변함없이 우리 사회를 변화의 열기로 밀어 올리고 있는 기술이 있다. 많은 사람이 생각하는 것처럼 ‘인공지능’이다. 인공지능은 ‘우리 사회의 어떤 부분을 변화시킬 것인지’를 찾는 것이 무의미할 정도로 모든 부분을 바꾸고 있고, 바꿀 것이다. 우리의 소중한 문화유산 역시 예외일 수 없다.
인공지능은 전통적인 개발 방법과 다르다. 기존의 모든 개발은 사람이 프로그램의 작동법을 100% 알려주는 방식이다. 하지만, 인공지능은 학습 데이터를 모아서 던져주고 작동하는 방법을 프로그램이 알아서 찾게 한다. 이 과정을 ‘학습한다’고 한다. 하지만, 이 학습 과정은 생각만큼 간단하지 않다. 수많은 시행착오를 겪는다. 보통 공개되어 있는 수학적 공식을 사용해 학습하라고 명령을 내리면 짧게는 몇 분, 길게는 몇 달 컴퓨터가 혼자서 학습을 하고 스스로 작동하는 방법을 찾아낸다. 그렇지만 제대로 찾지 못하는 경우가 상당히 많다. 그럼 ‘다시 다른 수학적 공식으로 학습하라.’고 명령을 내려야 하는 지난한 과정을 거쳐야 한다.
 〈커먼크롤(commoncrawl.org)〉 (출처: 커먼크롤)
〈커먼크롤(commoncrawl.org)〉 (출처: 커먼크롤) 
이 과정에서 핵심은 데이터이다. ChatGPT 같은 똑똑한 인공지능 프로그램을 만들려고 하면 우리가 상상하는 것보다 훨씬 많은 데이터가 필요하다. ChatGPT 같은 영어를 기반으로 하는 인공지능뿐만 아니라, 네이버에서 만드는 클로버 같은 한글 기반의 인공지능 서비스까지 대부분의 똑똑한 인공지능은 ‘커먼크롤’의 자료를 이용한다.
‘크롤링(crawling)’은 프로그램이 인터넷 사이트를 돌아다니면서 글들을 자동으로 가지고 오는 것을 말한다. 구글과 네이버 같은 검색 사이트의 기본 원리이기도 하다. 네이버와 구글은 문서 내에 있는 링크를 따라다니면서 크롤링을 통해 다른 사이트의 글과 이미지를 자동으로 가져온다. 이후 불필요한 태그(tag) 등을 제거한 후 자신의 서버에 저장해 둔다. 사용자가 특정 단어를 입력하면 자신의 서버를 살펴보고 일부를 보여 준 후 원문 사이트로 링크를 걸어주는 것이 검색 사이트라고 할 수 있다.
크롤링과 비슷한 용어로는 ‘스크랩핑(scrapping)’이 있는데 주로 특정한 목적을 가지고 특정 영역만 잘라서 가지고 오는 것을 뜻한다. 기준이 정확히 있는 것은 아니지만 다른 사이트의 페이지 전체를 가져오면 주로 크롤링이라고 이야기하고, 페이지의 일부분만 가지고 온다고 하면 보통 스크랩핑이라고 이야기한다.
크롤링은 대표적으로 파이썬의 ‘BeautifulSoup’라는 라이브러리를 많이 이용한다. 일반인이 클릭 몇 번으로 할 수 있는 것은 아니고 파이썬 프로그래밍을 할 줄 알아야 이용 가능하다. 하지만, BeautifulSoup을 이용한다고 해도 대규모로 데이터를 가지고 오는 것이 쉬운 일이 아니다. 먼저, 사이트마다 페이지를 분석해 BeautifulSoup의 소스를 조금씩 변경해 줘야 하며 구글 같은 사이트는 자신의 지적 재산권을 보호하기 위해 크롤링 접근을 막기 위한 다양한 장치를 두고 있다. 즉, 대규모로 크롤링하여 데이터를 모으는 것은 생각만큼 간단하지가 않다. 그래서 많이 이용하는 것이 ‘커먼크롤’이다.
커먼크롤은 원래 인공지능 개발을 위한 자료는 아니다. ‘요즘 시대에 인류의 자산이라고 할 수 있는 인터넷의 글을 백업 받아서 보존해야 한다.’는 생각을 가진 시민단체의 자료이다. 커먼크롤은 인터넷에 있는 수많은 데이터를 모은 후 월 단위로 무료로 공개하여 개인이나 회사가 따로 데이터를 수집할 필요 없게 해 주는 비영리 단체이다. 2008년 이후 인터넷을 돌아다니며 데이터를 모으고 있으며 아마존 S3에 보관하고 있다. 3600만 개의 도메인에서 34억 개의 웹 페이지를 백업 받아 놓은 것으로 알려져 있다.
인공지능 개발 시 학습 데이터로 커먼크롤을 기본적으로 학습시키고 구글, 메타(페이스북), 네이버 등은 추가로 자신들의 사이트에 올라온 자료를 또다시 학습시키는 것으로 알려져 있다. 그러나 자신의 데이터뿐만 아니라 인터넷에 올라온 자료는 저작권에 상관없이 무분별하게 학습시키는 것은 공공연한 비밀이다. 치열한 인공지능 경쟁에서 이기기 위해 우선은 저작권 소송을 당하는 위험을 감수하고 남의 자료, 나의 자료 할 것 없이 자료를 모으고 이를 통해 학습시키고 있다.
하지만, 이런 방법은 한계에 다다르고 있다. 내년 정도면 ChatGPT를 포함한 대부분의 인공지능이 인터넷에서 구할 수 있는 자료를 다 학습하고 더 이상 학습할 자료가 없기에 발전에 한계가 있을 수밖에 없다는 지적이 계속 나오고 있다. 그렇기 때문에 인공지능 업체들은 인터넷에서 데이터를 모으는 작업 외에도 다양한 방법으로 데이터를 모으기 위해 혈안이 되어 있으며 할 수 있는 모든 방법을 동원하고 있다.
예를 들어, 펜실베이니아대학교(University of Pennsylvania)의 연구진은 ‘에고넷(egonet)’ 프로젝트를 진행하고 있다. 지원자들은 평상시 머리에 작은 액션캠을 달고 생활을 하고, 스스로 찍은 영상에 본인이 어떤 일을 하려고 했던 것인지, 어떤 상황인지 등을 주요 장면마다 설명을 달아주고 있다. 매우 고단하고 지루한 작업일 것이다. 연구원들은 이런 데이터를 모아 인공지능을 학습시키고 있다.
 〈아마존이 운영하는 메캐니컬 터크(https://www.mturk.com)〉 (출처: mturk)
〈아마존이 운영하는 메캐니컬 터크(https://www.mturk.com)〉 (출처: mturk)
이런 것을 전문적으로 해 주는 사이트도 있다. 쇼핑몰 뿐만 아니라 인공지능 기술로도 유명한 아마존에서 운영하는 메캐니컬 터크(Mechanical Turk)이다. 원래는 클라우드 소싱 사이트로 시작했으나 요즘에는 주로 인공지능과 관련된 클라우드 소싱을 하고 있다. 기업이 인공지능을 개발하기 위해서는 수많은 사진, 동영상, 글이 필요한데 메캐니컬 터크에 의뢰를 하면 회원으로 등록한 사람들에게 연락을 해 다양한 자료를 받아준다. 수많은 데이터에서 각각의 이미지나 동영상에 이것이 어떤 상황, 어떤 물체라고 하나하나 태그를 달아주어 인공지능 학습에 도움을 줄 수 있게 도와준다. 그 외 의견 등도 취합해 준다.
예를 들어, 인간은 길을 가다가 앞에 리어카를 끄는 할머니가 나오면 밀어주는 것이 좋다고 당연히 생각하지만, 인공지능은 위험한 할머니가 위험 물체를 밀고 있다고 판단해 피해야 한다고 생각할 수 있다. 일반적으로 큰 물체가 움직이면 피해야 한다고 학습되었기 때문이다. 다양한 사진이나 영상을 보여주고 이런 경우 다음에 어떤 행동을 하면 좋은지 메캐니컬 터크 회원들에게 답을 구할 수 있다. 인간의 상식에 관해서도 질문과 답변이 필요한 경우는 수없이 많다. 특정 질문 외에도 좀 더 난도가 높은 복합 질문도 있다. ‘인공지능이 이 행동 다음으로 어떤 일을 하는 것이 좋을 거 같습니까?’ ‘이것이 어떤 장면인 거 같습니까’ 등 질문은 얼마든지 있다. 메캐니컬 터크를 벤치마킹한 국내에 있는 유사한 사이트로는 클라우드웍스 (www.crowdworks.kr)가 있다.
재미있는 것은 구글의 전략이다. 우리는 사이트를 가입하거나 로그인 할 때 아래와 같은 화면을 자주 보았을 것이다.
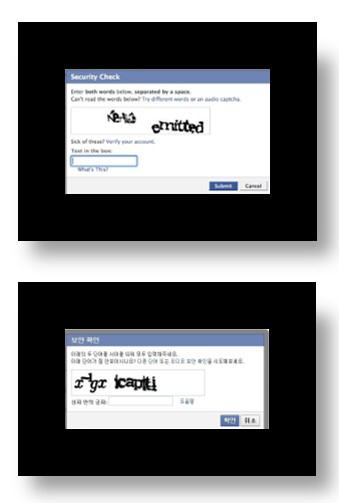 〈리캡차〉 (출처: google)
〈리캡차〉 (출처: google)
‘리캡차(reCAPTCHA)’라고 이야기하는데 구글이 운영하는 프로그램으로 사용자에게 뒤틀어지거나 배경 속에 혼재되어 있는 단어 이미지를 보여준 뒤, 보이는 대로 단어를 입력하라고 한다. 컴퓨터 프로그램을 이용해 자동으로 수많은 계정을 생성하는 것을 막기 위해 컴퓨터가 읽기 어려운 글자를 보여주고 입력을 유도해 컴퓨터를 통한 자동 가입인지, 정상 가입인지를 구분하는 기술로 알려져 있다. 하지만, 이는 표면적인 기능일 이유일 뿐이고 구글이 이 프로그램을 운영하는 진짜 이유는 다른 곳에 있다.
리캡차는 시기에 따라 화면이 조금씩 다르며 물어보는 내용도 조금씩 다르지만 공통적인 것이 하나 있다. 꼭 두 가지를 물어본다는 것이다. 왜 그럴까?
이 글의 주제와 연결 시켜 보면 눈치 빠른 분들은 구글이 이 프로그램을 운영하는 진짜 이유를 알아 차릴 수 있었을 것이다. 구글이 이 프로그램을 운영하는 진짜 이유는 고서(古書)를 통해 데이터를 얻기 위해서이다. 앞에서 이야기 한 것처럼 인터넷에 있는 데이터 확보는 거의 다 끝나가고 있다. 물론, 계속 인터넷에서 정보가 생산되고 있지만 그것만으로는 부족하다. 양질의 데이터를 얻기 위해서는 책에서 정보와 데이터를 얻어야 한다.
요즘 출간된 책의 글자를 인식시키는 것은 어렵지 않으나 고서는 난도가 높다. 리캡차는 구글이 보유하고 있는 고서 스캔 데이터에서 컴퓨터가 자동 인식 실패한 글자 이미지를 따온 뒤 사이트에 가입하거나 로그인하려고 하는 사용자에게 보여준다. 고서의 문자는 컴퓨터는 읽을 수 없으나 사람은 읽을 수 있는 경우가 많기 때문이다. 두 개를 물어보는 이유는 첫 번째로 물어보는 글자는 이미 판독이 완료된 글자이고, 두 번째가 구글이 원하는 데이터로, 판독이 되지 않아 사용자에게 어떻게 보이는지 물어보고 싶은 글자이다. 첫 번째를 맞히면 두 번째도 정확히 입력할 가능성이 높기에 몇 명 이상의 사람이 같은 글자를 입력할 경우 해당 글씨를 판단 완료한다.
앞에서 설명한 것처럼 인공지능은 데이터를 던져주고 컴퓨터에게 자동으로 학습하라고 지시한다고 설명했다. 그리고 이 데이터의 근간은 누구나 사용할 수 있도록 공개된 커먼크롤이라고 설명했다. 인공지능 성능의 가장 큰 변수는 데이터이다. 남들이 가지고 있지 않은 고문서 같은 문화유산이 인공지능 발달에 얼마나 큰 기여를 할 수 있는지를 짐작할 수 있다. 공개되어 있는 수학 공식은 대동소이(大同小異)해 학습 방법이 동일하고, 데이터가 동일한 상태에서 차별화를 추구할 수 있는 인공지능 개발 방법은 차별화된 우리의 문화유산을 학습시키는 것이 될 수 있기 때문이다. 즉, 가장 앞선 기술이라고 할 수 있는 인공지능 시대에 역설적이게도 오래된 우리의 문화유산의 중요성이 더 커질 수 있다. 우리의 문화유산이 인공지능 개발에 큰 도움을 주고, 우리의 문화유산을 학습시키는 것은 우리의 문화유산을 지키면서도 큰 의미가 있는 것이 된다.
 〈한국국학진흥원에서 소장하는 고서와 고문서 등
〈한국국학진흥원에서 소장하는 고서와 고문서 등
모든 자료를 볼 수 있는 사이트(https://search.koreastudy.or.kr/)〉
(출처: 한국국학진흥원)
한국국학진흥원 등에서 제공하는 다양한 연구 자료와 발간 자료는 인공지능 시대 관련 기업들과 관련자들에게는 큰 도움이 될 수 있다. 대부분의 기업이 ChatGPT 같은 뛰어난 인공지능을 개발하지는 않는다. 대부분 ChatGPT 같은 이미 공개되어 있는 서비스를 이용하고자 할 것이다. 하지만, ChatGPT는 범용적인 서비스일 뿐 우리 문화유산에 대해서 특화된 서비스가 아니다. 사용하는 용어도 다를 것이다. ‘유산’이라고 하면 문화 쪽에서는 ‘문화유산’을 주로 생각하지만 일반적으로는 부모님이 돌아가셨을 때 남기는 ‘재산’을 생각하는 경우가 더 많을 것이다. 그렇기 때문에 ChatGPT는 문화유산을 중요하게 다루는 기업이나 단체에서는 바로 사용하기 어렵다.
이런 기업들이 요즘 큰 관심을 많이 가지는 기술이 ‘RAG’라는 기술이다. RAG가 주목받은 것은 2024년 상반기부터이다. 인공지능 분야에서도 최신 기술이지만, 요즘에는 인공지능을 이야기하면서 RAG라는 단어를 빼놓고 말할 수는 없을 정도로 빠르게 주목받고 있다. 국내뿐만 아니라 해외에서도 RAG가 엄청나게 관심을 받고 있어 설립한 지 얼마 안 된 관련 회사의 기업 가치가 수천억으로 정해지는, 쉽게 납득하기 어려운 현상까지 발생하고 있다.
RAG는 ChatGPT 같은 서비스에 내가 가지고 있는 문서를 연결시켜 사용할 수 있는 기술이다. RAG는 ‘retrieval-augmented generation’의 약어이다. Retrieval은 search와 마찬가지로 ‘검색’이라는 뜻이고, augment는 ‘증가’ 혹은 ‘증강’이라는 단어이다. Generation은 생성형 인공지능을 뜻한다. 우리나라 말로 쉽게 풀어 쓰면 ‘검색으로 성능이 좋아진 생성형 인공지능 서비스’ 정도로 이야기할 수 있을 것 같다. ChatGPT 같은 사이트에 질문을 하기 전에 내가 가지고 있는 자료를 먼저 참고한 후 ChatGPT에 물어보는 기술 정도로 이해하면 크게 틀리지 않는다.
RAG를 쉽게 이해하려고 하면 학교 시험과 비교해 보면 쉽다. 현재의 ChatGPT는 책을 완전히 외워서 시험지에 답변을 다는 방식이라고 할 수 있다. 이에 비해 RAG는 시험을 볼 때 관련된 자료를 보고 의도를 파악해 시험지에 답을 쓰는 방식이라고 이해하면 된다. 우리가 시험 볼 때 참고 자료 없이 외워서 시험을 보는 것이 훨씬 더 어렵고 문제의 의도를 파악하기 어려운 것처럼 ChatGPT 같은 서비스는 우리가 원하는 정확한 답변을 하기 어렵다. 공개되어 있는 ChatGPT에 RAG를 결합하면 조금 더 우리 회사가 원하는 답변을 할 수 있다.
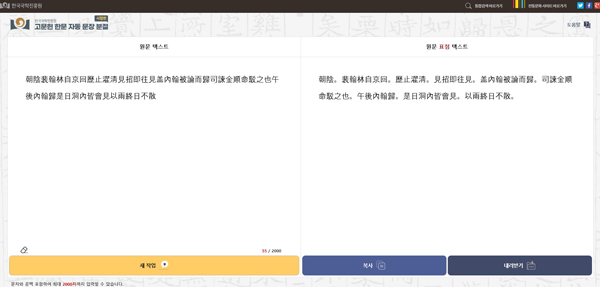 〈한국국학진흥원에서 서비스하는 인공지능에 기반한 고문헌 한문 문장 분절 (https://ai.ugyo.net/space/)〉
〈한국국학진흥원에서 서비스하는 인공지능에 기반한 고문헌 한문 문장 분절 (https://ai.ugyo.net/space/)〉
(출처: 한국국학진흥원)
예를 들어, 우리가 가진 문화유산에 대한 다양한 PDF, MS-Word, Excel, 그리고 아래 한글 자료를 올리면 이 자료를 참고해 ChatGPT에 물어볼 수 있다. 즉, 내가 기존에 PDF로 문화유산에 대한 자료를 올려놓았을 경우, ChatGPT는 부모님이 물려주신 재산에 대한 정보가 아니라 내가 알려준 문화유산과 ChatGPT가 가지고 있는 문화유산에 대한 정보를 결합해 보여 줄 수 있기 때문에 훨씬 더 정확하고 풍부한 결과를 보여 줄 수 있다.
RAG는 기술적으로는 크게 2개의 구조로 구성되어 있다. 내가 올린 문서들을 검색해 적당한 정보를 찾는 부분과 이 검색된 결과를 참고해 ChatGPT 등에 연결해 콘텐츠를 생성하는 기능이다. RAG가 요즘 LLM(대규모 언어 모델)의 미래라고 하면서 크게 관심 받는 이유는 몇 가지가 있다.
첫째, RAG는 최신성을 유지할 수 있다. ChatGPT 같은 사이트는 커먼크롤 등을 활용해 인터넷에서 구할 수 있는 자료를 최대한 수집하는 방식으로 학습을 하기 때문에 엄청난 데이터를 학습하며 오랜 시간이 걸린다. 그렇기 때문에 이런 서비스들이 가지고 있는 정보는 최신 정보일 수 없다. 유료로 제공되고 있는 ChatGPT 4는 2023년 4월까지 수집된 정보를 기반으로 학습을 한 것이다. 그렇기 때문에 최신 정보를 물어보면 모르거나 엉뚱한 답변을 할 수밖에 없는 구조이다. (다만, 최근에는 ChatGPT도 최신 정보를 반영하기 위해 일부 RAG 기술을 사용해 이 문제를 해결하려고 하고 있다). RAG 기술을 이용하면 외부 사이트와 연결해 최신 정보를 반영한 답변을 할 수 있다.
둘째, RAG는 전문적인 답변을 할 수 있다. ChatGPT에 질문을 계속하다 보면 어느 순간 비슷한 답변을 말만 바꿔서 답변을 하고 있다는 것을 느끼는 순간이 있게 된다. ChatGPT가 학습한 내용이 범용적인 내용이라 더 이상 깊이 있는 정보가 없기 때문이다. 하지만, RAG는 내가 올린 문서를 참고해 답변을 해 준다고 했다. 우리 회사나 단체만 가지고 있는 문화유산에 대한 정보를 올려놓으면 외부에 공개되지 않으면서 우리 직원이나 회원에게만 노출되어 정보 유출 없이 인공지능이 적절한 답변을 할 수 있다.
셋째, 비용 절감을 할 수 있다. ChatGPT 제작 비용은 공개되지 않았지만 학습시키는데 1조 정도가 들었다는 이야기가 있을 정도로 막대한 비용이 들어간다. 그렇기 때문에 요즘 많은 기업은 비용 절감에 고민을 하고 있다. 이에 대한 대안으로도 RAG가 언급된다. 자신들에게 최적화된 인공지능이 필요하다고 ChatGPT 같은 서비스를 또 개발하는 것이 아니라 ChatGPT에 RAG 기술을 연동해 사용하는 방안이 비용을 크게 줄일 수 있기 때문이다.
넷째, 환각(hallucination) 현상을 줄일 수 있다. ChatGPT 같은 사이트의 가장 큰 단점으로 지적하는 것이 환각현상이다. ChatGPT 같은 서비스는 기본적으로 수학적 통계를 이용해 글자를 생성하면서 답변을 하는 것이다. 그렇기 때문에 그럴듯한 잘못된 답변을 할 수 있다. 이를 환각현상이라고 한다. 하지만, 내가 올린 정보를 활용해 답변을 할 경우 환각효과를 크게 줄일 수 있다는 장점이 있다.
다섯째, 저작권 갈등을 줄일 수 있다. 인공지능 서비스는 지금 천문학적인 비용의 소송에 시달리고 있다. ChatGPT 개발사인 오픈 AI는 뉴욕타임스(The New York Times)로부터 저작권 소송을 당했으며, 세계 최대의 이미지 저작권 사이트인 게티이미지(www.gettyimages.com)는 그림을 그려주는 인공지능으로 유명한 스테이블 디퓨전(Stable Diffusion)의 개발사인 스테빌리티 AI(Stability AI)를 상대로 1,200억 원 규모의 소송을 제기했다. 인공지능 경쟁에서 이기기 위해서 저작권을 뒤로하고 우선 크롤링을 통해 데이터를 확보하고 학습시켜 기술경쟁에서 이기겠다는 생각을 가지고 있는 상황에서 저작권 관련 소송은 더 늘어날 것이 확실하다. 저작권을 가지고 있는 업체가 지적하는 부분은 자신들의 저작권을 이용해 학습을 했다는 것인데, 사실 구글 같은 검색도 저작권자의 사이트를 복사해 검색 사이트의 서버에 보관하고 있는 것은 똑같다. 하지만 큰 차이는 검색 사이트는 사용자를 저작권자의 사이트로 넘겨주어 저작권자의 사이트에서 광고를 보게 하는 방법으로 사업을 도와주는데 비해 ChatGPT같은 사이트는 저작권자의 자료를 사용해 학습했지만 저작권자의 사이트로 넘어가는 링크가 없기 때문에 더욱 갈등이 커지고 있는 것이다. 하지만, RAG는 나에게만 해당 정보가 보이기 때문에 저작권 문제에서 비교적 자유로울 수 있다.
이외에도, RAG는 내가 올린 문서를 검색 후 답변의 정확도를 높여주는 방식 외에도 다양하게 활용할 수 있다. 예를 들어, 내가 장기 휴가를 떠나고 싶을 경우 인공지능에게 언제, 어디로 휴가를 가는 것이 가장 좋을지 물어볼 수 있을 것이다. RAG에게 물어보면 실시간으로 여행사와 항공사의 홈페이지에 연결해 가격 등을 비교해 볼 수 있을 뿐만 아니라 우리 회사 인사 시스템에 접속해 나의 휴가 가능 일정까지 체크해 복합적 판단을 통해 최적의 휴가 일정과 장소를 추천해 줄 수 있을 것이다. 또한, 똑같은 질문을 한다고 해도 인사 시스템과 연동해 직급과 부서에 따라 다른 답변을 해 줄 수도 있다. 이렇듯 다양한 장점이 있기에 RAG는 인공지능의 미래라고 이야기하면서 큰 관심을 받고 있다.
 〈주영한국문화원에서는 우리 문화유산의 디지털 데이터와 인공지능을 활용한
〈주영한국문화원에서는 우리 문화유산의 디지털 데이터와 인공지능을 활용한
미디어 아트 특별전 ‘Digital Heritage, now! AI with you‘를 2024년에 개최하였다.〉
(출처: 한국문화원)
위에서 살펴본 것처럼 우리의 문화유산은 인공지능학습의 주요 거름이 되어 누구나 볼 수 있는 아름다운 꽃이 되어 피어날 수 있으며, ChatGPT 등과 연결된 RAG는 이 세상에 하나뿐인 나와 우리 회사만을 위한 지니 램프가 되어 나의 모든 것을 들어줄 수 있다. 문화유산이 반영된 인공지능을 그 사회가 가지고 있는 것과 그렇지 않은 것은 생각보다 우리 사회에 더 많은 영향을 줄 수 있다. 문화는 모든 것의 근간이기 때문이다. 우리 문화가 반영되지 않은 ChatGPT는 우리와 생각을 같이 하는 인공지능일 수 없다. 미국 사람이 미국에서 한국말을 열심히 공부해 우리나라 말을 잘한다고 해도, 한국 문화와 정서를 온전히 이해할 수 없다면 결국은 한국인일 수 없는 것처럼 ChatGPT가 아무리 우리말을 잘한다고 해도 결국은 우리의 문화와 정서를 온전히 이해할 수 없다면 결국은 한국인을 위한 ChatGPT라고 할 수는 없을 것이다. 인공지능 시대에도 우리의 문화유산은 소중하며, 우리의 문화유산은 인공지능 시대에 더욱더 활용도와 가치가 높은 존재가 될 것으로 보인다.
참고) http://ko.wikipedia.org/wiki/CAPTCHA
집필자 소개
- 조중혁
- 인공지능으로 박사 수료를 하였습니다. 『인공지능 생존수업』을 포함해 IT 전문책을 14권 집필했고, 이 중 『인터넷 진화와 뇌의 종말』은 문화체육관광부 선정 '올해의 우수 도서’이며, 고등학교 국어 교과서에도 본문이 수록이 되어 있습니다. 통신사에 근무 중이며, 대외 활동으로는 경기도청 4차산업혁명위원회 Data, network, AI 분과 위원장 등 공적인 영역에서 강의, 자문, 평가, 컨설팅 등을 진행하고 있습니다.
![]()
36605 경상북도 안동시 도산면 퇴계로 1997 대표전화 : 054) 851-0700




| 시기 | 동일시기 이야기소재 | 장소 | 출전 |
|---|